
TensorRT-LLM ソフトウェアを実行する NVIDIA Hopper ベースのシステムが、生成 AI 用に世界で最も強力なプラットフォームを実現できることを業界標準のテストで実証
公式発表:NVIDIA は、生成 AI の推論に関する業界標準のテストにおいて、世界最速のプラットフォームを実現しました。
最新の MLPerf ベンチマークにおいて、NVIDIA TensorRT-LLM (大規模言語モデルにおける複雑な推論作業を高速化し、簡素化するソフトウェア) は、GPT-J LLM における NVIDIA Hopper アーキテクチャ GPU の性能を、わずか 6 ヶ月前の結果と比べて約 3 倍にまで向上させました。
この劇的な高速化は、NVIDIA のチップ、システム、およびソフトウェアのフルスタック プラットフォームが、生成 AI の実行時に求められる厳しい要件に対応できる能力を備えていることを実証しています。
大手企業は、自社のモデルを最適化するために TensorRT-LLM を採用しています。また、TensorRT-LLM のような推論エンジンを含む一式の推論マイクロサービスである NVIDIA NIM によって、企業は NVIDIA の推論プラットフォームをこれまで以上に簡単に展開しています。
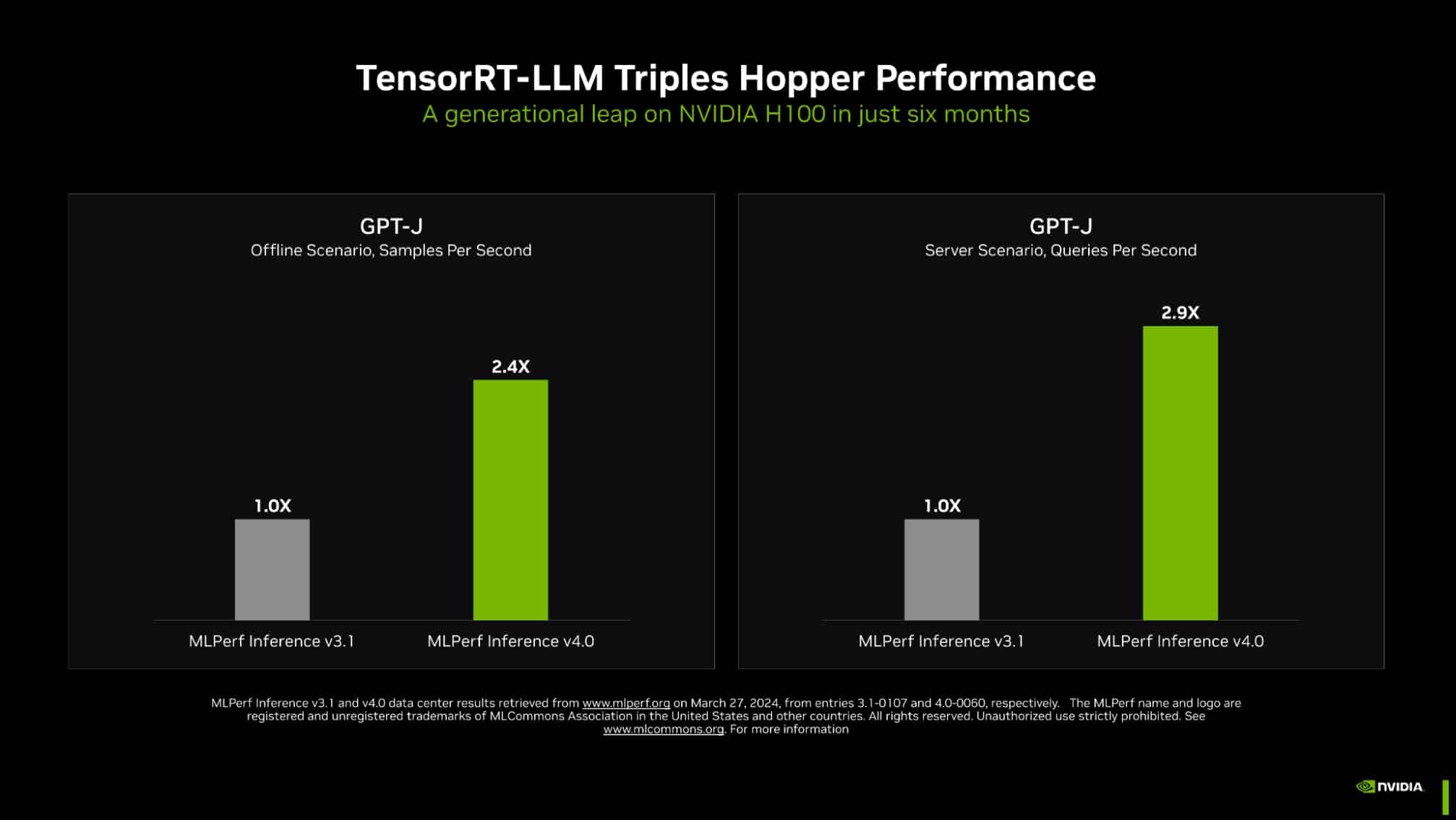
生成 AI の水準を高める
NVIDIA H200 Tensor コア GPU (メモリを強化した最新の Hopper GPU) 上で動作する TensorRT-LLM は、MLPerf の生成 AI に関するこれまでで最大のテストにおいて、最速の推論実行を実現しました。
この新しいベンチマークでは、最先端の大規模言語モデルで 700 億のパラメータを有する Llama 2 の最大バージョンが使用されています。このモデルは、9 月のベンチマークで初めて使用された GPT-J LLM と比べ、10 倍以上の規模となります。
メモリを強化した H200 GPU が MLPerf に初登場し、TensorRT-LLM を使用して MLPerf の Llama 2 ベンチマークの最高記録となる最大 31,000 トークン/秒を達成しました。
H200 GPU の結果には、カスタムのサーマル ソリューションによる最大 14% の向上も含まれています。これは、システム ビルダーが NVIDIA MGX 設計に適用している標準的な空冷機能を上回るイノベーションの一例で、結果的に Hopper GPU の性能は新たな高みへ引き上げられました。
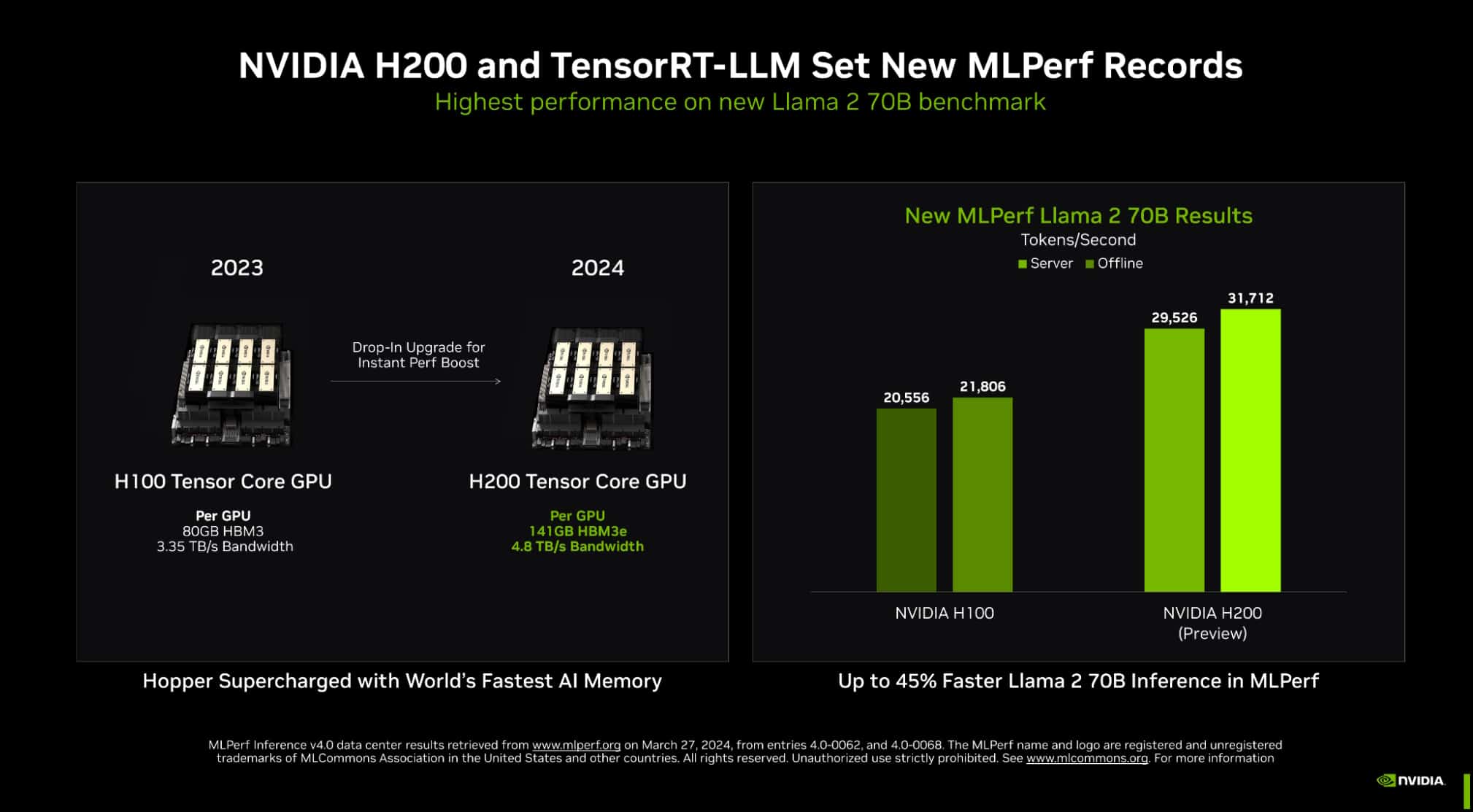
NVIDIA Hopper GPU のメモリ増強
NVIDIA は現在、H200 GPU をお客様向けにサンプル出荷しており、第 2 四半期に出荷を行う予定です。H200 GPU は、20 社近くの主要なシステム ビルダーやクラウド サービス プロバイダーから間もなく入手できるようになります。
H200 GPU は、4.8TB/秒で動作する 141GB の HBM3e メモリを搭載しています。H100 GPU と比較すると、このメモリは 76% 増えており、43% 高速です。このアクセラレータは、H100 GPU と同じボードやシステムに装着可能であり、同じソフトウェアを使用します。
HBM3e メモリにより、H200 GPU 1 基で Llama 2 70B モデル全体を最高のスループットで実行できるようになるため、推論を簡素化して高速化することが可能になります。
GH200 はさらに多くのメモリを搭載
NVIDIA GH200 Superchip にはさらに多くのメモリ (144GB の HBM3e を含む最大 624GB の高速メモリ) が搭載されており、Hopper アーキテクチャ GPU と電力効率に優れた NVIDIA Grace CPU を 1 つのモジュールに統合しています。NVIDIA アクセラレータは、HBM3e メモリ技術を採用する初の製品です。
5 TB/秒に近いメモリ帯域幅を持つ GH200 Superchip は、レコメンダー システムのようなメモリ集約型の MLPerf テストなどで、卓越したパフォーマンスを発揮しました。
あらゆる MLPerf テストを席巻
アクセラレータ単位で見ると、Hopper GPU は、MLPerf 業界ベンチマークの最新ラウンドで AI 推論に関するあらゆるテストを席巻しています。
これらのベンチマークは、生成 AI、レコメンダー システム、自然言語処理、音声認識、コンピュータ ビジョンなど、現在特に一般的な AI のワークロードとシナリオを網羅しています。NVIDIA は、最新のラウンドを含め、MLPerf のデータセンター推論ベンチマークが 2020 年 10 月に開始されて以来のすべてのラウンドで、すべてのワークロードに関する結果を発表してきた唯一の企業です。
継続的なパフォーマンス向上は、推論のコスト削減につながります。世界中に展開された数百万基の NVIDIA GPU において、推論は、日常の処理の大部分を占めるようになりつつあります。
可能性をさらに拡大
可能性の限界を押し広げるために、NVIDIA は、ベンチマークの「オープン部門」という先進的な AI 手法をテストする特別なセクションで、3 つの革新的な技術を披露しました。
NVIDIA のエンジニアは、NVIDIA A100 Tensor コア GPU で初めて導入された構造化されたスパース性と呼ばれる技術 (計算を削減する手法) を使用して、Llama 2 の推論で最大 33% の高速化を実現しました。
2 つ目のオープン部門のテストでは、AI モデル (この場合は LLM) を簡素化して推論のスループットを向上させる手法であるプルーニングを使用して、推論を最大 40% 高速化できたことが確認されました。
最後に、DeepCache と呼ばれる最適化手法により、Stable Diffusion XL モデルの推論に必要な計算の量を削減し、パフォーマンスを 74% も高速化できたことが実証されました。
これらの結果はすべて、NVIDIA H100 Tensor コア GPU 上で実行されました。
ユーザーにとって信頼できる情報
MLPerf のテストは透明性が高く客観的であるため、ユーザーはその結果を信頼し、的確な情報に基づいた購入判断を行うことが可能になります。
NVIDIA のパートナー各社が MLPerf に参加しているのは、それが AI のシステムやサービスを評価する顧客にとって貴重なツールだと知っているからです。今回のラウンドで NVIDIA AI プラットフォームを使用して結果を発表したパートナーには、ASUS、Cisco、Dell Technologies、富士通、GIGABYTE、Google、Hewlett Packard Enterprise、Lenovo、Microsoft Azure、Oracle、QCT、Supermicro、VMware (最近 Broadcom によって買収)、Wiwynn が含まれます。
NVIDIA がテストで使用したソフトウェアはすべて、MLPerf リポジトリで入手可能です。これらの最適化は、GPU アプリケーション向けの NVIDIA のソフトウェア ハブである NGC や、NIM 推論マイクロサービスを含むサポートされた安全なプラットフォームである NVIDIA AI Enterprise にて利用可能なコンテナーに継続的に組み込まれます。
次なるイノベーション
生成 AI のユース ケース、モデル サイズ、データセットは拡大し続けています。そのため MLPerf も進化し続けており、Llama 2 70B や Stable Diffusion XL のような人気モデルによる実環境でのテストが追加されています。
LLM モデル サイズの急拡大と歩調を合わせるように、NVIDIA の創業者/CEO であるジェンスン フアン (Jensen Huang) は、先週の GTC で、「NVIDIA Blackwell アーキテクチャ GPU が、数兆パラメータの AI モデルで求められる新たなレベルのパフォーマンスを実現するでしょう」と説明しました。
大規模言語モデルの推論は難しく、専門知識だけでなく、NVIDIA が Hopper アーキテクチャ GPU と TensorRT-LLM を使って MLPerf で実証したフルスタックのアーキテクチャも必要とされます。今後、まだまだ多くのイノベーションが生まれるでしょう。
MLPerf ベンチマークと今回の推論ラウンドの技術的詳細をご覧ください。
※本発表資料は米国時間 2024年 3 月 27 日に発表されたブログの抄訳です。