 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
自動運転車で使用されるような最近のディープ ニューラル ネットワークでは、膨大な量のコンピューティング能力が要求されます。現在では、NVIDIA DGX-1 のような 1 台のコンピューターで、2010 年の世界最大級のスーパーコンピューター (「Top 500」、2010 年) に匹敵するコンピューティング パフォーマンスを達成できます。これは前例のない技術的進歩ですが、最近のニューラル ネットワークに必要なコンピューティング能力とトレーニングに必要なデータセット サイズを考慮に入れると、十分ではありません (図 1)。

図 1. ニューラル ネットワークのコンピューティングの複雑性が急速に増しています。
これは、特に自動運転車のように、安全が極めて重要で、検出精度要件がインターネット業界よりもはるかに高いシステムに当てはまります。このようなシステムは、天候条件、視野、路面の状態にかかわらず、不具合なく動作することが求められます。
このレベルの認識精度を達成するため、発生しうる運転操作、天候、状況の条件すべての実例などからなるサンプル データセットで、ニューラル ネットワークをトレーニングする必要があります。実際、このことは数ペタバイトのトレーニング データにつながります。さらに、このような膨大なデータセットから、全ての事例を漏れなく学習するためには、ニューラル ネットワーク自体を十分に大きくする (大量のパラメータからなる大きなモデルを使用する) 必要があります (Goodfellow 他、2016 年)。このシナリオでは、データサイズが n 倍増加すると、コンピューティング要件は n2 倍増大し、複雑なエンジニアリング上の課題が生じます。1 個の GPU でトレーニングする場合、ニューラル ネットワークのサイズによっては、トレーニングに (数十年とは言わないまでも) 数年かかる可能性もあります。また、コンピューター ハードウェアだけでなく、ストレージ、インターコネクト、アルゴリズムに関する検討事項も課題となります。
この記事では、研究/開発の推進を支援する AI IT インフラ部門のリソース プランニングに役立つ情報として、自動運転で必要となる大きなニューラル ネットワークをトレーニングするには、どの程度の計算量が必要なのかを調査します。
十分なデータ量はどの程度か
すべてのメーカーは、データの収集、サンプリング、圧縮、ストレージの課題に対して互いに大きく異なるアプローチを取っています。各メーカーが選択する正確な詳細情報やデータ量は公開されていませんが、自動運転車の台数と計測機器に関する情報を公開しているメーカーもあります。この情報とデータ収集プロセスに関する 4 つの控えめな前提条件を組み合わせることにより、データ量を大まかに推定することができます。各事例におけるコンピューティング要件を計算するため、この推定を利用しました。
自動運転車の台数
以前は Google の自動運転車プロジェクトであった Waymo などの企業は、数十台から数百台の自動車を保有し、毎日データを収集していると報告しています。2016 年 12 月に、Waymo は車両を 100 台増やすことを発表し (「Google’s Waymo adds 100 Chryslers」、2016 年)、2017 年 5 月には、300 万マイルのデータを収集していることを報告しました (「Waymo – On the road」、2017 年)。他のメーカーも、同等の台数の車両を生産しています。2017 年 6 月に、General Motors は 130 台の自動運転車を生産し、短期間でこれを 180 台に増やす予定であることを発表しました (「GM completes production」、2017 年)。2016 年 8 月に、Ford は、100 台の自動運転車を配備したことを発表しました(「The self-driving Ford is coming」、2016 年)。
上記の事例を考慮に入れて、この記事では控えめな推定として自動運転車の台数を 100 台とします。
前提条件 1: 自動運転車の台数 = 100
重要なのは、物理的な車両によって収集されるデータのみを使用してこの課題を解決できると考えている研究者はほとんどいないということです。Waymo などの多くの企業は、シミュレーションに多額の投資をしており、上記の台数よりも数桁多い仮想データ収集車両を構築しています。この記事の執筆時点で、Waymo は、コンピューター シミュレーションを利用して生成された 10 億マイルを超えるデータを収集しています。このことは、Waymo の仮想車両が、数千台のシミュレーション車両から構成されていることを示唆しています。
データ収集期間
テクノロジがまだ実用化されていないため、路上での走行に適するアルゴリズムをトレーニングするために必要なデータ量を正確に推定することは不可能です。以下の計算は、公開されている情報に基づいています。
この記事の執筆時点で、Waymo は以下のデータを有することを報告しています (「Waymo – On the road」、2017 年)
- 300 万マイル = 約 483 万 km の実際のテスト走行
- 10 億マイル = 約 16 億 km のシミュレーション テスト走行
- 1,000 マイル = 約 1,600 km あたり 0.2 の機能解除率 (平均して 5,000 マイル = 約 8,000 km ごとに人間が介入する必要があった)
この機能解除率は、製品としては明らかに高すぎます。このことは、300 万マイルのテスト走行が不十分であることも示しています。この数値は、必要な初期データセットの控えめな推定値として使用します。
Waymo は、新たに追加した車両によって、7 か月で 100 万マイルのデータを収集できるようになったとも報告しました。 これは 21 か月で 300 万マイルに相当します。 ここでも、この数値を控えめにするため、期間を 12 か月に大幅に切り下げ、1 台あたり毎日 8 時間、年間 260 日 (年間の営業日数) のみの走行として説明します。
前提条件 2: データ収集の期間 = 1 年間の営業日数 = 2080 時間/車両
これは、5 台のカメラを搭載した 100 台の自動車で、1 年に 100 万時間を超えるビデオ録画データが生成されることを示しています。このデータは、取得され、自動車からデータ センターに転送され、保存され、処理されてトレーニングに使用されます。教師あり学習アルゴリズムに使用するため、人間がそれらのデータに注釈を付けます。データへの注釈付けを担当するチームの規模が不十分な場合、すべての歩行者、自動車、車線、その他の詳細にマークを付ける作業が大きなボトルネックとなることがあります。
1 台の自動車によって生成されるデータ量
自動運転車のユース ケースでデータ収集に使用される一般的な自動車には、複数のセンサーが搭載されます (「NVIDIA Automotive」、2017 年、Liu 他、2017 年)。これには、レーダー、カメラ、LIDAR、超音波センサー、多様な自動車センサーなどのテクノロジが含まれ、そのデータは自動車のコントローラー エリア ネットワーク (CAN)、Flexray、車載イーサネット、その他多数のネットワークを通じて配信されます。
一般的なテスト車両には、コンピューター システムが可視性と冗長性を高められるよう、複数のカメラ、レーダー、その他のセンサーが搭載されています。これにより、悪天候や個々の構成機器の故障に対応することができます (図 2)。

図 2. 一般的な自動運転車は、カメラ、レーダー、
LIDAR など、複数のセンサーから構成され、
360 度の視野が自動車に提供されます。
特定のメーカーやサプライヤーの計測機器に関する正確な詳細情報は公開されていませんが、主要なサプライヤーは課題の規模を示す情報を提供しています。Dell EMC と Altran によって公開された論文 (Radtke、2017 年) は、2,800 メガビット/秒で動作する 1 台の正面レーダーのみによって1 時間あたり 1.26 TBを超えるデータが生じ、一般的なデータ収集自動車では 1 日あたり 30 TB を超えるデータが生成されることを明らかにしました。同様に、30 フレーム/秒 (fps) で動作する 2 台のメガピクセル カメラ (1 ピクセルあたり 24 ビット) によって、1 秒あたり 1,440 メガビットのデータが生じます。したがって、5 台のカメラ構成では、1 日あたり 24 TB を超えるデータが生成される可能性があります。
さまざまな自動運転車の正確な車載計測機器に関する公開情報が限られていることを考慮に入れると、データ量の前提条件は極めて控えめにしなければなりません。シンプルにするため、また最終的なコンピューティング要件が誇張されないように、サラウンド カメラによって生成されるデータのみを考慮に入れます。さらに、多くの場合 5 台を超えるカメラが搭載されますが、自動車には 5 台のカメラのみが搭載されていると仮定します。この構成では、一般に 30 fps で動作する 2 メガピクセル カメラを使用します。
この極端にシンプル化した構成でも、毎時間 3 TB を超える未加工のビデオデータが生成されます。ここでは、(ハードウェアやサンプリング レートの差異を考慮に入れて、)さらに 1 時間あたり 1 TBに減らします。
前提条件 3: 1 台の自動車によって生成されるデータ量 = 1 TB 以上/時間
データの前処理
最後の前提条件は、一般に未加工のビデオ ストリームに対して行うデータの前処理に関係します。ニューラル ネットワークのパフォーマンスに大きな影響を与えずにデータ量を安全に減らすために実行できる以下の 2 つのステップがあります。
- データ サンプリング: 個々のビデオ フレーム間の相関性が高いため、研究の初期段階で課題である計算量を制御できるよう、入力データセットの再サンプリングを検討することができます。実際には実施されないかもしれませんが、30 fps から 1 fps にデータを再サンプリングすることによって、コンピューティングに使用されるデータセットサイズが 30 分の 1 に減少することが推定されます。
- 圧縮: 同様に、圧縮でデータが失われないことは稀であるため、実際には圧縮を利用できない可能性があります。ここでは、計算に使用するデータ量を減らすため、非常に極端な 70 分の 1 の圧縮比率を仮定します。ただし、実際上は画像品質が大幅に低下するために利用できない可能性があります。ここでも、最終的なデータ量の推定を控えめにするためにのみ、このように仮定しています。
次に、上記の 2 つの数値をかけると、データ削減係数は約 0.0005 になります。
前提条件 4: 前処理によるデータの削減 = 未加工のデータの約 0.0005
前処理後の総データ量
ここで、これまでにかなり控えめに推定した前提条件を組み合わせると、1 台の自動車によって毎時間 1 TB 以上のデータが生じ、1 日あたり 8 時間、年間 260 営業日にわたって走行している 100 台の自動車によって、204.8 PB のデータが生じます。
未加工の総データ量 = 204 PB
前のセクションで説明したように、トレーニングを実行可能にするために、このデータは十分に処理され、おそらく再サンプリングによって削減されます。これにより、データ量はかなり減少して 104 TB になります。
前処理後の総データ量 = 104 TB
トレーニングに実際にかかる期間
前処理後の総データ量は、100 TB と算出されました。この数値は、トレーニング プロセスに関して何を意味するでしょうか。自動車検出ネットワークのニューラル ネットワーク アーキテクチャは公開されていないため、さらに計算を進められるよう、いくつかの最新の画像分類ネットワークを利用します。このようなネットワークは、概念上、歩行者検出や、オブジェクト分類、経路計画などのタスクに使用されるソリューションに非常に似ています。
コンピューティング負荷が非常に低い画像分類モデルの 1 つである AlexNet (Krizhevsky 他、2012 年)と非常に小規模な ImageNet データセット (Russakovsky 他、2014 年) を組み合わせて実行すると、1 台の Pascal GPU で約 150 MB/秒のスループットが達成されます。ResNet 50 (He 他、2016 年) などのさらに複雑なネットワークの場合、この数値は、約 28 MB/秒に近くなります。Inception V3 (Szegedy 他、2016 年) などの最新のネットワークでは、約 19 MB/秒になります。
ここで、自動車検出ネットワークが ImageNet データで使用されるネットワークと同様のエポック数に収束すると仮定した場合 (計算を簡単にするために 50 エポックを使用します)、1 基の GPU では以下の期間がかかります。
- 50 エポック × 104 TB のデータ/19 MB/秒 = Inception-v3 のようなネットワークで 1 回トレーニングするために 9.1 年
- ResNet-50 のようなネットワークでは 6.2 年
- AlexNet のようなネットワークでは 1.2 年
NVIDIA DGX-1 のような最新のディープラーニング システムは、ほぼリニアにスケールするように設計されており、最大 8 倍のコンピューティング能力を提供します、。しかし、単体のシステムでは課題は解決されません。8 基の Tesla P100 (Pascal) GPU を使用しても、以下のトレーニング時間がかかります。
- ImageNet V3 または類似のネットワークでは 1.13 年
- ResNet 50 または類似のネットワークでは 0.77 年
- AlexNet または類似のネットワークでは 0.14 年
新しい Volta GPU アーキテクチャの導入によって、一部の課題に対する処理を高速化できますが (執筆時点で、Tesla V100 上で ResNet 50 のトレーニングは 2.5 倍速くなります)、課題の規模が大きいことに変わりはありません。特にこの点を考慮に入れると、実際には、データセットからの情報に対処するため、はるかに大規模なネットワークが必要になる可能性があります (Goodfellow 他、2016 年)。
トレーニングのためにチームにはどの程度のコンピューティングが必要か
前のセクションにおいて、単体のシステムでは自動運転に必要な膨大なデータとコンピューティング能力に対応できないことを示しました。Volta GPU を搭載した DGX-1 など、さらに集積度の高いコンピューティング システムの出現により、現在では、桁外れのコンピューティング リソースを提供するクラスター化ソリューションを構築することができます。
これまでの数値的な推定により、上記のような対応が必要であることは明らかです。実験結果を 2 年間待つ必要がある場合、非常に優れた人材からなる最大のチームでさえも、成功することは期待できません。100 日でも長すぎます。チームが効果的に作業するため、この反復処理期間は (数時間にすることは難しいとしても) 数日に短縮する必要があります。さらなる計算の目的のために、7 日を目標として仮定します。また、チームが同時に作業する複数のメンバーから構成される場合、すべてのメンバー (または少なくともチームの一部、20% と仮定) が、合理的な期間内に実験結果を得られるようにする必要があります。どの程度のコンピューティング能力が必要であるかを把握するため、さらに計算してみましょう。30 人で構成される、かなり控えめな人数のチームがあり、そのうち 6 人のみが特定の時点でジョブを提出すると仮定すると、トレーニング期間を 7 日にするために以下のシステムが必要になります。
- Inception V3 または類似のネットワークでは 356 台の DGX-1 Pascal システム (チーム メンバー 1 人あたり約 10 台のシステム)
- ResNet 50 または類似のネットワークでは 241 台のシステム (チーム メンバー 1 人あたり 8 台のシステム)
- AlexNet または類似のネットワークでは 45 台のシステム (チーム メンバー 1 人あたり 2 台のシステム)
Tesla V100 (Volta) GPU を搭載した DGX-1 が 2.5 倍高速であることを示す最新の Volta ベンチマークを適用すると、上記の数値は次のようになります。
- Inception V3 または類似のネットワークでは 142 台の DGX-1 Volta システム (チーム メンバー 1 人あたり約 4 ~ 5 台のシステム)
- ResNet 50 または類似のネットワークでは 97 台のシステム (チーム メンバー 1 人あたり 3 台のシステム)
- AlexNet または類似のネットワークでは 18 台のシステム (チーム メンバー 1 人あたり 1 台のシステム)
表 1 に、これまでの推定と前提条件、加えて、より現実的な推定をまとめます。
| 前提条件 | 非常に控えめな推定 | より現実的な推定 |
|---|---|---|
| 自動運転車の台数 | 100 | 125 |
| データ収集期間 | 1 年間の営業日数/8 時間 | 1.25 年間の営業日数/10 時間 |
| 1 台の自動車で生成されるデータ量 | 1 TB/時間 | 1.5 TB/時間 |
| 前処理によるデータの削減 | 0.0005 | 0.0008 |
| 研究チームの人数 | 30 | 40 |
| ジョブを提出するチーム メンバーの比率 | 20% | 30% |
| 目標トレーニング期間 | 7 日 | 6 日 |
| 収束に必要なエポック数 | 50 | 50 |
| 計算 | ||
| 未加工の総データ量 | 203.1 PB | 595.1 PB |
| 前処理後の総データ量 | 104 TB | 487.5 TB |
| 1 台の DGX-1 Volta システム (8 GPU) でのトレーニング期間 | 166 日 (Inception V3) 113 日 (ResNet 50) 21 日 (AlexNet) |
778 日 (Inception V3) 528 日 (ResNet 50) 194 日 (AlexNet) |
| チームの目標トレーニング期間を達成するために必要なマシンの台数 (Volta GPU を搭載した DGX-1) | 142 (Inception V3) 97 (ResNet 50) 18 (AlexNet) |
1556 (Inception V3) 1056 (ResNet 50) 197 (AlexNet) |
表 1. コンピューティング要件の計算に使用した前提条件の概要と、前提条件のわずかな差異による計算結果の変化を示す代替的シナリオ
直線的拡張の課題
上述したすべてのコンピューティングの推定は、クラスターによって完全な直線的拡張を実現できることを前提としています。これは、GPU の数を増やすにつれて、トレーニング期間がそれに比例して短縮されることを意味します。この記事全体を通して、この拡張を実現するためのメカニズムとして Dean 他 (2012 年) によって説明されたデータ並列性に言及しています。したがって、GPU の数を倍にするとトレーニング時間が 50% に短縮されるはずですが、これは困難なことです。
クラスターに複数のゲーミング グラフィックス カードを取り付けるだけで、GPU の数とトレーニング期間の関係が完璧な直線になることは期待できません。それどころか、PCI-e バスにいくつかの GPU を接続する場合、2 ~ 3 枚以上にカードの数を増やすと、ほとんどの自動車画像分割ネットワークにおいてパフォーマンスの上昇が制限されることが確認されます (これは、ネットワークのコンピューティングの複雑性とパラメーターの数によって異なります)。
このセクションでは、この振る舞いの理由を簡単に説明し、インフラストラクチャに対する主要な設計上の考慮事項を示します。また、追加情報を得るための適切な資料も紹介します。さらに詳細な情報については、NVIDIA DGX-1 システム アーキテクチャに関するホワイト ペーパー (「NVIDIA DGX-1 System Architecture」、2017 年)を参照してください。
ネットワーキング
(コード品質の問題を除き) 拡張が直線的にならない最も基本的な原因の 1 つは、通信オーバーヘッドです。
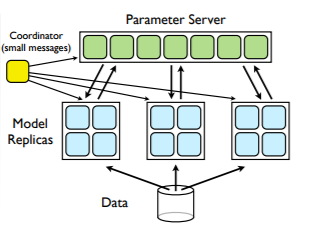
図 3. Dean 他 (2012 年) で説明
された同期データ並列性
データ並列性 (Dean 他、2012 年)を利用し、複数の GPU でニューラル ネットワークをトレーニングするには、すべての GPU が同じモデルのコピーとデータの小さなサブセットを取得する必要があります (図 3)。ニューラル ネットワークからの転送が完了した後に、データのコンピューティングと交換が開始されます。この段階で、GPU は非常に限られた時間内に膨大な量のデータを交換する必要があります。
GPU がネットワークを通じて結果を返すよりも交換に長い時間がかかる場合、すべてのマシンは、その通信が完了するまでアイドル状態で待機する必要があります。
ほとんどの場合、通信ボトルネックを回避するために必要なデータ速度は、PCI-e ネットワークの能力を超えていることが判明しました。この課題に対処するため、NVIDIA は NVLink と呼ばれる専用 GPU 相互接続を開発しました。NVLink の 2 回目のリリースでは、Tesla V100 GPU 1 基あたり 300 GB/秒を超える双方向の帯域幅を提供しています。
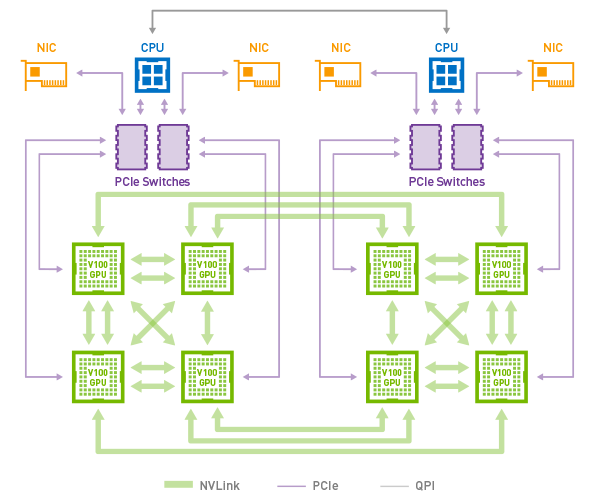
図 4. Volta GPU を搭載した DGX-1 の NVLink トポロジ
NVLink は、1 台のマルチ GPU システム内の通信の課題に対処します。これにより、アプリケーションでは、DGX-1 で最大 8 個の GPU まで拡張できます (図 4)。これは、PCI-e 相互接続のみを備えた類似のシステムよりもはるかに優れています。複数のマシンに拡張するには、マルチノード通信とネットワーク トポロジでの InfiniBand の役割を検討することが不可欠です。複数のサーバーによる最高のトレーニング パフォーマンスのため、図 5 に示すように、利用できる総帯域幅を最大にする、完全 Fat-Tree トポロジのネットワーク設計を検討してください (Capps、2017 年)。

図 5. ディープラーニング ワークロード向けに推奨されるネットワーク トポロジ
NVLink と InfiniBand は通信媒体ですが、それ自体は分散ディープラーニング用にすぐに利用可能なメカニズムを備えていません。この課題に対処するため、NVIDIA Collective Communications Library (NCCL) は、クラスター内の GPU 通信の複雑性を隠蔽し、すべての一般的なディープラーニング フレームワークと (さまざまなレベルで) 統合されます。
アルゴリズムとソフトウェア
NCCL はニューラル ネットワークの実装に組み込む必要がある唯一のロジックではありません。ほとんどすべてのディープラーニング フレームワークではワークロードの並列化が可能ですが、そのために必要なエンジニアリング作業量は互いに異なります。さらに、ディープラーニング フレームワークごとに実装の品質と発展のスピードが異なり、変化やバグへの対応が比較的簡単な場合もあれば、複雑な場合もあります。最後に、すべてのディープラーニング フレームワークには、すぐに利用可能ないかなるレベルのサポートも付属していません。
一連のソフトウェア ツールを構築し、維持するためにエンジニアリング分野の人材が必要ですが、このような人材がプロジェクトの開始時に軽視され、急に人材の必要性に気づくことが非常に多くあります。このプロセスをサードパーティーにアウトソーシングするか、かなりの人数のソフトウェア エンジニアを採用しない限り、研究員がツールセットの構築と保守に責任を負うことになります。これは、研究員の主要な専門技術ではなく、また主要な業務とすべきではありません。
AI の研究を加速し、(ディープラーニング フレームワークの保守と最適化ではなく) 企業が自動運転車のアルゴリズムの開発に集中できるよう、NVIDIA は、毎月のリリース サイクルですべての主要なディープラーニング フレームワークに対する最適化済みコンテナーを提供しています。このコンテナによって、変化し続けるディープラーニング環境の複雑性を管理する必要がなくなるだけでなく、卓越したパフォーマンスも提供されます。NVIDIA の最適化とテストにより、チームのエンジニアリング作業が大幅に減少します (図 6)。
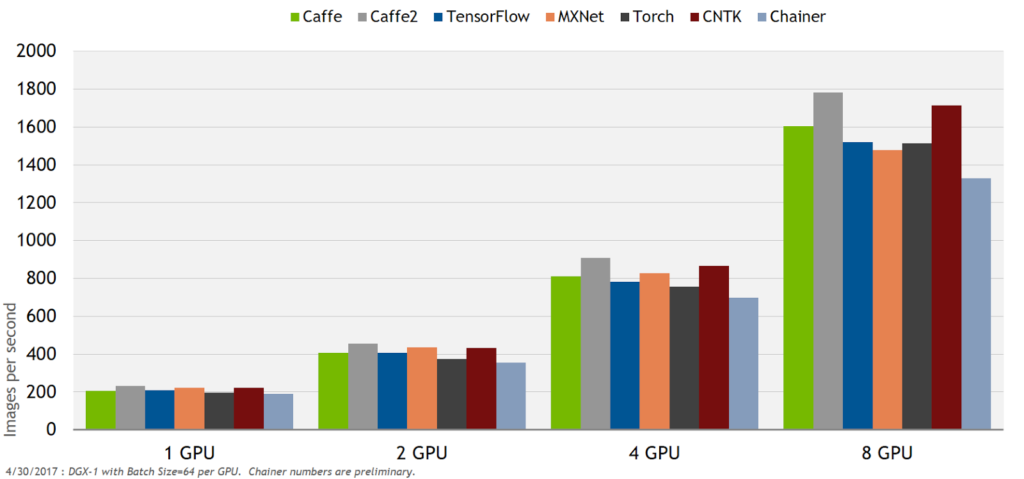
図 6. NVIDIA によって最適化されたディープラーニング フレームワークと Pascal GPU を搭載した DGX-1 による ResNet 50 FP32 のパフォーマンス
ストレージ
軽視されることが多いもう 1 つのソリューションの要素は、ストレージです。原則として課題はシンプルであり、GPU に十分なデータを提供し、常にビジー状態にすることです。データ ロード パイプラインでのあらゆる遅延によって、必然的に GPU のアイドル時間が生じ、プロセス全体が大幅に遅延します。データ転送の帯域幅を軽視してはなりません。特に高解像度画像を処理している場合、単一のノードで 3 GB /秒を超えるデータが処理されることはまれではありません。
比較的小さなデータセットの場合、課題はもっとシンプルです。ニューラル ネットワークは各トレーニング エポックで同じデータにアクセスするため、データは高パフォーマンスの SSD (またはもっと小さなデータセットでは RAM ) 上でローカルにキャッシュし、ローカル SSD の速度で GPU にデータを転送することができます (ただし、最初のエポックでは、初めにネットワーク ファイル サーバーにアクセスする必要があることに注意してください)。このようなソリューションは、DGX-1 などのディープラーニング システムで既に幅広く配備されています。
自動車に関係する場合、課題はもっと複雑です。上記の推定に基づいて、最適なケースのシナリオでも 100 TB のデータを扱うことになります。データを DGX-1 に 1 度転送してから、複数のエポックにわたって体系的に再利用できる場合、DGX-1 で使用されるローカル キャッシュが有益です。しかし、自動車のデータセットは、トレーニング マシンが持つローカル ストレージの容量をはるかに超えているため、ローカル キャッシュの利用には限界があります。この場合、比較的パフォーマンスの高いストレージ バックエンドが必要なことは明らかです。NVIDIA は、多くの場合 HPC ファイル システムと共に、フラッシュ (Robinson、2017 年) ストレージやフラッシュ アクセラレーション ストレージを配備するケースの増大を確認しています。
CPU とメモリー
CPU は、データのロード、ロギング、スナップショット、拡張プロセスに加えて、トレーニング プロセスを調整するために極めて重要な役割を果たします。CPU が、GPU によって処理されるデータの速度よりも遅い場合、GPU はアイドル状態になります。 ImageNet のような比較的シンプルな処理の場合でも、8 基の Pascal GPU によって、サーバーグレードの CPU ソケット全体が簡単に過負荷状態になりうる点に注意することが重要です (Goyal 他、2017 年)。これは、Samsung Research などのグループにとって非常に重大な問題となったため、各グループは、ニューラル ネットワーク自体で利用できる GPU リソースが減少するにもかかわらず、データ拡張パイプラインを GPU に移行するプロセスに着手しました (Goyal 他、2017 年)。
さまざまな CPU 構成のベンチマーキングを行ったところ、エンドツーエンドのトレーニング パフォーマンスへの軽視できない影響が確認されました。RAM でも同様のバランスを維持する必要があります (GPU に搭載されているメモリーの 2 倍~ 3 倍)。
エンジニアリング ワークフローの他の段階における計算
AI エンジニアリング ワークフローとは、ディープラーニング モデルの大規模なトレーニングよりもはるかに広範な概念です。候補モデルの効果的なプロトタイプ作成、テスト、最適化、配備のためには、チームにツールを提供する必要があります (図 8)。これらすべてのステップで、大量のコンピューティング リソースが要求されます。適切なツールによってサポートされない場合、大規模な研究チームを結成してもあまり意味がありません。
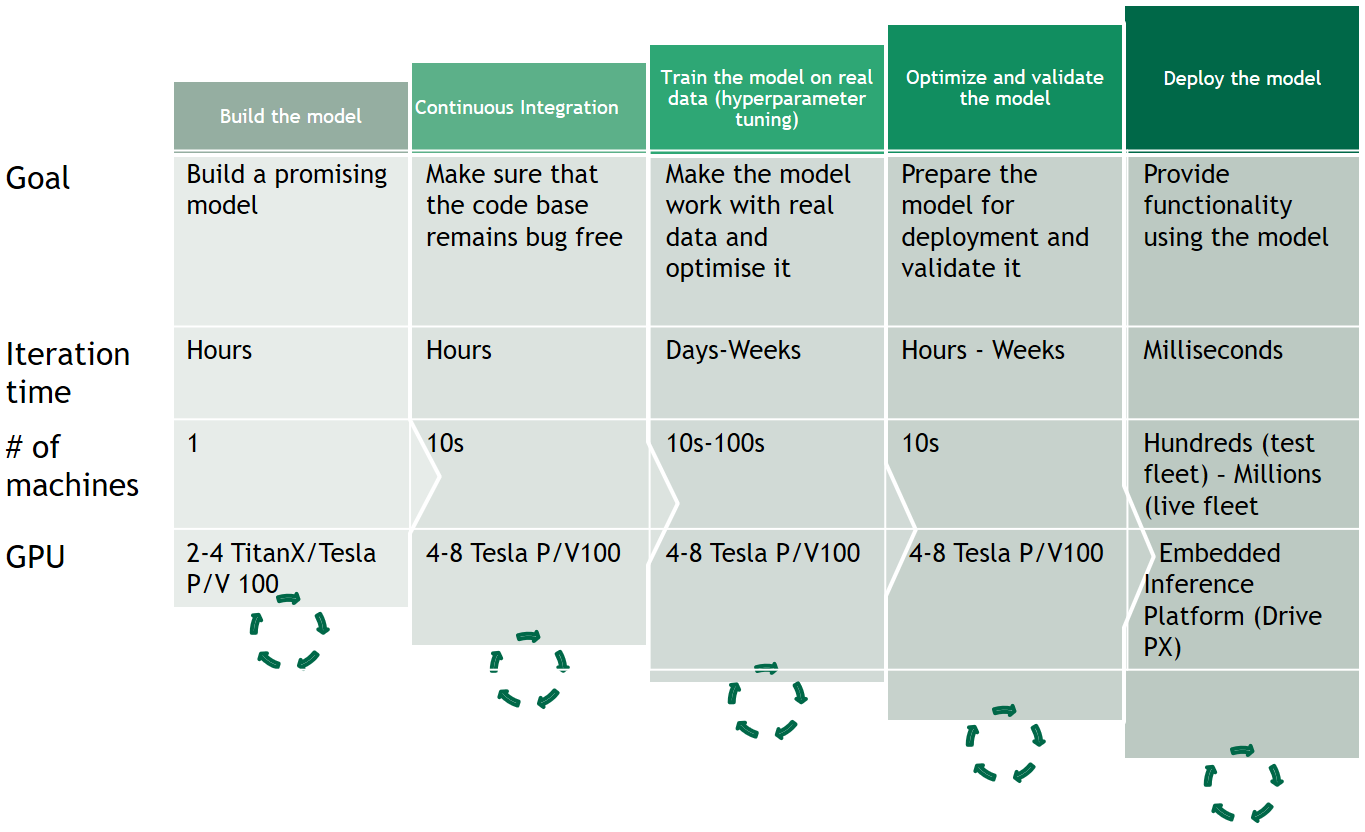
図 8. 自動車 AI モデルの開発とテストのためのさまざまな段階
課題はこれだけではありません。データのエンジニアリングと処理、データの転送とストレージ、データへの注釈付け (300 万マイルの走行データを考慮に入れると大量のタスクになります)、プロトタイプ作成、テストおよび最適化のためのインフラストラクチャは、チームの規模に比例して増強する必要があります。
規模の計画
自動運転車を実現するために使用されるディープ ニューラル ネットワークのコンピューティング要件は膨大です。この記事ブログでは、計算のすべての段階でデータ量を大幅に (場合によっては 1 桁以上) 減らしましたが、それでも計算結果は、少数の GPU では自動運転車の研究を十分に実施できないことを明確に示しています。Tesla V100 GPU を搭載した DGX-1 のような強力なデバイスでも、100 TB のデータセットを処理する場合、1 回のトレーニングに数か月かかります。大規模な分散トレーニングを利用することは避けられません。このインフラストラクチャとそれをサポートするソフトウェアの構築は簡単ではありませんが、実現できないことではありません。
人間の歴史の中で初めて、複雑な自動運転車のトレーニングに対して十分なコンピューティング能力が獲得されました。明らかに、必要なのはコンピューティング リソースだけではありません。事業を管理するため、研究チーム、データ エンジニアリング チーム、システム チームを結成する必要があります。データを収集するために多数の車両を製造して配備し、結果を検証してから、その結果を車両に統合する必要もあります。ロジスティクスと財務上の多くの課題が生じますが、エンジニアリング/研究の取り組みによって (つまり予算と時間をかけることによって)、この非常に重要な課題に対する解決策を見いだすことができます。
課題の複雑性の評価、分散トレーニングと大規模なモデル検証の課題に関する議論、独自の AI チームの編成についてサポートが必要な場合は、当社にお問い合わせください。
AI トレーニングワークフローの主要な要件の詳細については、NVIDIA DGX-1 システム アーキテクチャ ホワイトペーパーを参照してください。
最後に、この記事で使用した計算に基づく検証に関心がある場合は、このスプレッドシートをコピーし、独自のユース ケースを反映するために使用する前提条件を変更して、自社の AI チームのコンピューティング要件を推定するために利用することができます。
参考資料
Chintala, S. (2017 年). Deep Learning Systems at Scale. GPU Technology Conference.参照元: http://on-demand.gputechconf.com/gtc/2016/presentation/s6227-soumith-chintala-deep-learning-at-scale.pdf
Dean, J.,Corrado, G.,Monga, R.,Chen, K.,Devin, M.,Mao, M.,…& Ng, A. Y. (2012 年). Large scale distributed deep networks. In Advances in neural information processing systems (pp. 1223-1231).
Gale, T., Eliuk, S., Upright, C. (2017 年). High-Performance Data Loading and Augmentation for Deep Neural Network Training, GPU Technology Conference 2017, 参照元: http://on-demand.gputechconf.com/gtc/2017/presentation/s7569-trevor-gale-high-performance-data-loading-and-augmentation-for-deep-neural-network-training.pdf
GM completes production of 130 Bolt self-driving cars. (2017 年 6 月 13 日). 参照元: http://in.reuters.com/article/gm-autonomous/gm-completes-production-of-130-bolt-self-driving-cars-idINKBN1941P2
Goodfellow, I., Bengio, Y., & Courville, A. (2016 年). Deep learning.MIT press.
Google’s Waymo adds 100 Chryslers to self-driving fleet. (2016 年 12 月 19 日). 参照元: http://www.dailymail.co.uk/wires/afp/article-4048484/Googles-Waymo-adds-100-Chryslers-self-driving-fleet.html
Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., …& He, K. (2017 年). Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv preprint arXiv:1706.02677.
He, K., Zhang, X.,Ren, S., & Sun, J. (2016 年 10 月). Identity mappings in deep residual networks. In European Conference on Computer Vision (pp. 630-645).Springer International Publishing.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012 年). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097-1105).
Liu, S., Tang, J., Zhang, Z., & Gaudiot, J. L. (2017 年). CAAD: Computer Architecture for Autonomous Driving. arXiv preprint arXiv:1702.01894.
NVIDIA Automotive. (2017 年 10 月 1 日). 参照元: https://www.nvidia.com/ja-jp/self-driving-cars/
NVIDIA DGX-1 System Architecture – The Fastest Integrated System for Deep Learning. (2017 年).参照元: http://www.nvidia.co.jp/object/dgx-1-system-architecture-whitepaper-jp.html
Radtke, S. (2017 年 2 月 6 日). Addressing the Data growth challenges in ADAS /AD for simulation and Development. 参照元: http://stefanradtke.blogspot.de/2017/02/how-isilon-addresses-multi-petabyte.html
Robinson, J.,Real World AI: Deep Learning Pipeline Powered by FlashBlade. (2017 年 9 月 29 日). 参照元: https://www.purestorage.com/resources/type-a/real-world-ai.html
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., …& Berg, A. C. (2015 年). Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115(3), 211-252.
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016 年). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2818-2826).
The self-driving Ford is coming. (2016 年 8 月 16 日). 参照元: http://uk.businessinsider.com/fords-self-driving-cars-2021-2016-8?r=US&IR=T
Top 500, The List. (2010 年 6 月). 参照元: https://www.top500.org/lists/2010/06
Waymo – On the road. (2017 年).参照元: https://waymo.com/ontheroad







Pingback: NVIDIA(NVDA)と自動運転にはどんな関係が? | OKAKA!!